Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
Abstract
- Monocular 3D object parsing is highly desirable in various scenarios including occlusion reasoning and holistic scene interpretation
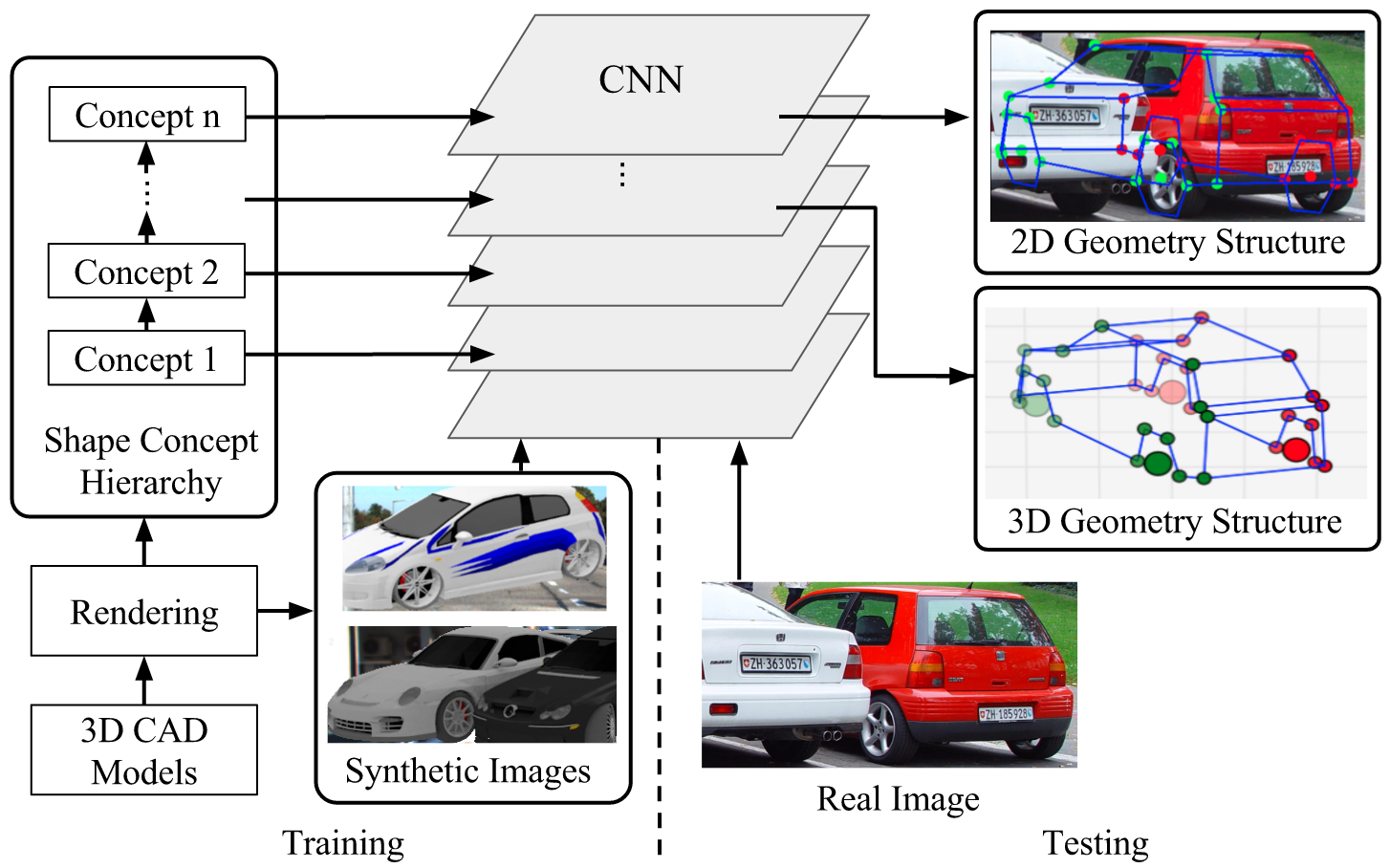
- We present a deep convolutional neural network (CNN) architecture to localize semantic parts in 2D image and 3D space while inferring their visibility states, given a single RGB image.
Introduction
- To illustrate this idea, we use 3D skeleton as the shape representation, where semantically meaningful object parts (such as the wheels of a car) are represented by 3D keypoints and their connections define 3D structure of an object category
-
We introduce a novel CNN architecture which jointly models multiple shape concepts including object pose, key-point locations and visibility in Section 3.
- We first formulate the deep supervision framework by generalizing Deeply Supervised Nets in Section 3.1.
- Section 3.2 presents one particular network instance where we deeply supervise convolutional layers at different depths with intermediate shape concepts
-
Section 3.3 proposes to render 3D CAD models to create synthetic images with concept labels and simulate the challenging occlusion configurations for robust occlusion reasoning
- We denote our network as “DISCO” short for Deep supervision with Intermediate Shape COncepts
Related work
3D Skeleton Estimation This class of work models 3D shape as a linear combination of shape bases and optimizes basis coefficients to fit computed 2D patterns such as heat maps [43] or object part locations [45]
3D Reconstruction A generative inverse graphics model is formulated by [15] for 3D mesh reconstruction by matching mesh proposals to extracted 2D contour
3D Model Retrieval and Alignment This line of work estimates 3D object structure by retrieving the closest object CAD model and performing alignment, using 2D images [44,1,18,23,40] and RGB-D data
Pose Estimation and 2D Keypoint Detection
Deep Supervision with Shape Concepts
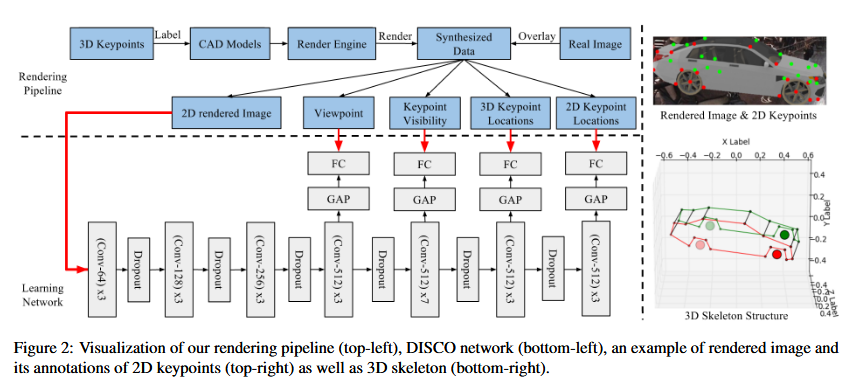
In the following, we introduce a novel CNN architecture for 3D shape parsing which incorporates constraints through intermediate shape concepts such as object pose, keypoint locations, and visibility information. Our goal is to infer, from a single view (RGB image) of the object, the locations of keypoints in 2D and 3D spaces and their visibility.
- Deep Supervision
- Our approach draws inspiration from Deeply Supervised Nets (DSN)


- Network Architecture
- To set up (2), we must first choose a sequence of necessary conditions for 2D/3D keypoint prediction with growing complexity as intermediate shape concepts.
- We have chosen, in order, (1) object viewpoint, (2) keypoint visibility, (3) 3D keypoint locations and (4) full set of 2D keypoint locations regardless of the visibility, inspired by early intuitions on perceptual organization
-
We impose this sequence of intermediate concepts to deeply supervise the network at certain depths as shown in Fig. 2 and minimize four intermediate losses li in (2), with other losses removed

-
Synthetic Data Generation