Time Series Anomaly Detection & RL time series
Prediction of Stock Moving Direction
Detecting Stock Market Anomalies
CVAE-Financial-Anomaly-Detection
Probabilistic reasoning and statistical analysis in TensorFlow
RL & SL Methods and Envs For Quantitative Trading
Big Data and Machine Learning for Finance
CVAE
CVAE (Conditional Variation Autoencoder)
- we are going to see how CVAE can learn and generate the behavior of a particular stock price action
- CVAE generates millions of points and whenever real price action veers too far away from the bounds of these generated patterns, we know that something is different
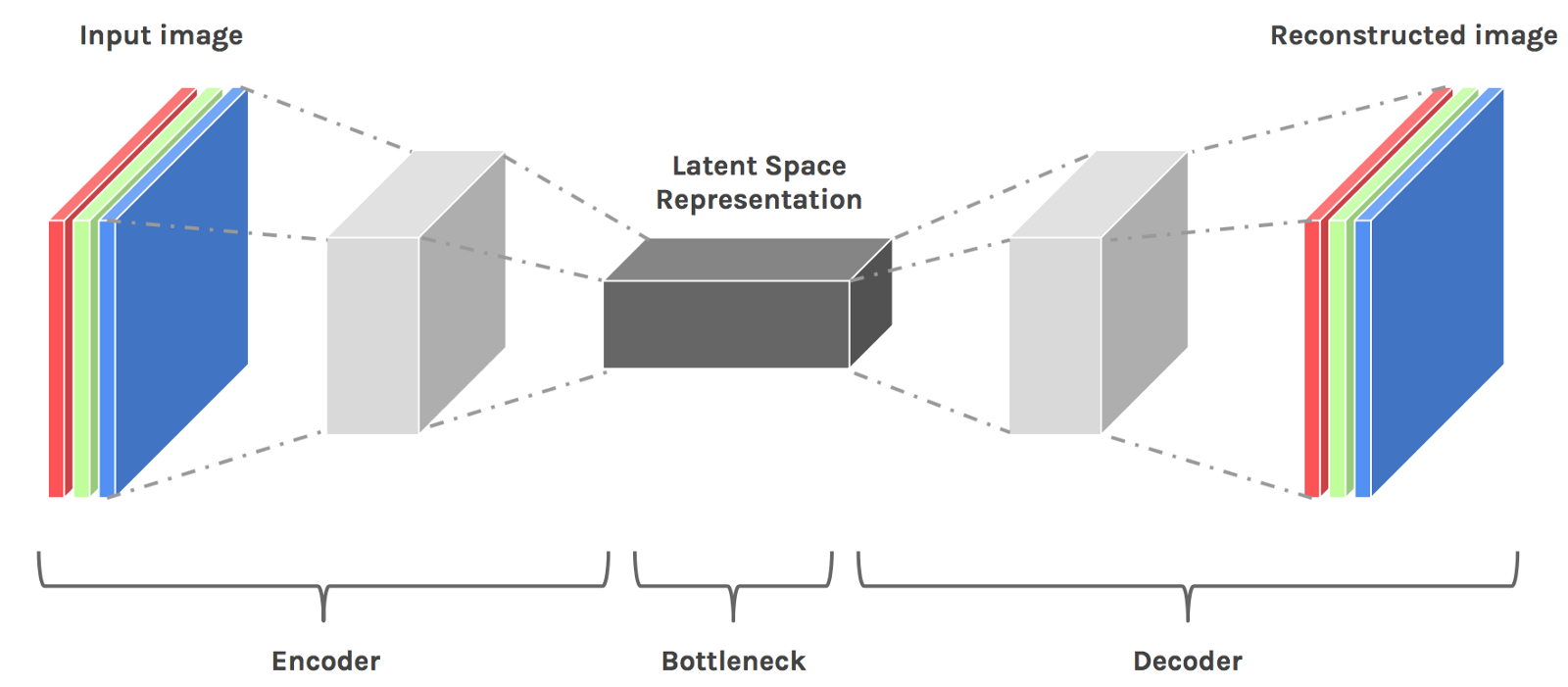
The Autoencoder can reconstruct Data
- The autoencoder is an unsupervised neural network that combines a data encoder and decoder
- The encoder reduces data into a lower dimensional space known as the latent space representation
- The decoder will take this reduced representation and blow it back up to its original size
- This is also used in anomaly detection. You train a model, feed new data into the encoder,compress it, then observe how well it rebuilds it
- If the reconstruction error is abnormally high, that means the model strugged to rebuild the data and you may have an anomaly on your hands
The Variatoinal autoencoder can generate Data
- The variational autoencoder adds the ability to generate new synthetic data from this compressed representation
- It does so by learning the probability distribution of the data and we can thus generate new data by using different latent variables used as input
The Conditional Variational Autoencoder(CVAE) Can generate Data by Lable
- With CVAE, we can ask the model to recreate data(synthetic data) for a particular label
- we can ask it to recreate data for a particular stock symbol
- we ask the decoder to generate new data down to the granularity of labels
Code Analysis
dow_30_symbols = ['AAPL']
# sklearn LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train = ["paris", "paris", "tokyo", "amsterdam"]
test = ["tokyo", "tokyo", "paris"]
print(le.fit(train).transform(test))
[2,2,1]
# np.utils.to_categorical is used to convert array of labeled data(from 0 to nb_classes-1) to one-hot vector.
In [1]: from keras.utils import np_utils
Using Theano backend.
In [2]: np_utils.to_categorical?
Signature: np_utils.to_categorical(y, num_classes=None)
Docstring:
Convert class vector (integers from 0 to nb_classes) to binary class matrix, for use with categorical_crossentropy.
# Arguments
y: class vector to be converted into a matrix
nb_classes: total number of classes
# Returns
A binary matrix representation of the input.
File: /usr/local/lib/python3.5/dist-packages/keras/utils/np_utils.py
Type: function
In [3]: y_train = [1, 0, 3, 4, 5, 0, 2, 1]
In [4]: """ Assuming the labeled dataset has total six classes (0 to 5), y_train is the true label array """
In [5]: np_utils.to_categorical(y_train, num_classes=6)
Out[5]:
array([[ 0., 1., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 1., 0., 0.],
[ 0., 0., 0., 0., 1., 0.],
[ 0., 0., 0., 0., 0., 1.],
[ 1., 0., 0., 0., 0., 0.],
[ 0., 0., 1., 0., 0., 0.],
[ 0., 1., 0., 0., 0., 0.]])
Keras Layer output merged -> How to concatenate two layers in keras?
from keras.models import Sequential, Model
from keras.layers import Concatenate, Dense, LSTM, Input, concatenate
from keras.optimizers import Adagrad
first_input = Input(shape=(2, ))
first_dense = Dense(1, )(first_input)
second_input = Input(shape=(2, ))
second_dense = Dense(1, )(second_input)
merge_one = concatenate([first_dense, second_dense])
third_input = Input(shape=(1, ))
merge_two = concatenate([merge_one, third_input])
model = Model(inputs=[first_input, second_input, third_input], outputs=merge_two)
model.compile(optimizer=ada_grad, loss='binary_crossentropy',
metrics=['accuracy'])

python KL divergence
import numpy as np
def KL(P,Q):
""" Epsilon is used here to avoid conditional code for
checking that neither P nor Q is equal to 0. """
epsilon = 0.00001
# You may want to instead make copies to avoid changing the np arrays.
P = P+epsilon
Q = Q+epsilon
divergence = np.sum(P*np.log(P/Q))
return divergence
# Should be normalized though
values1 = np.asarray([1.346112,1.337432,1.246655])
values2 = np.asarray([1.033836,1.082015,1.117323])
# Note slight difference in the final result compared to Dawny33
print KL(values1, values2) # 0.775278939433
KL divergence between two univariate Gaussians
KL divergence between two univariate Gaussians
- KL(p, q) = \log \frac{\sigma_2}{\sigma_1} + \frac{\sigma_1^2 + (\mu_1 - \mu_2)^2}{2 \sigma_2^2} - \frac{1}{2}