Policy Gradient Basic
Tensorflow gradient explaination
TF uses automatic differentiation and more specifically reverse-mode auto differentiation.
- There are 3 popular methods to calculate the derivative:
- Numerical differentiation
Numerical differentiation relies on the definition of the derivative: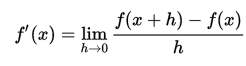 , where you put a very small h and evaluate function in two places. This is the most basic formula and on practice people use other formulas which give smaller estimation error. This way of calculating a derivative is suitable mostly if you do not know your function and can only sample it. Also it requires a lot of computation for a high-dim function.
, where you put a very small h and evaluate function in two places. This is the most basic formula and on practice people use other formulas which give smaller estimation error. This way of calculating a derivative is suitable mostly if you do not know your function and can only sample it. Also it requires a lot of computation for a high-dim function. - Symbolic differentiation
Symbolic differentiation manipulates mathematical expressions. If you ever used matlab or mathematica, then you saw something like this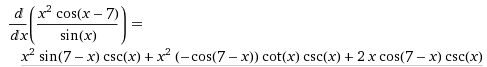
- Numerical differentiation
Here for every math expression they know the derivative and use various rules (product rule, chain rule) to calculate the resulting derivative. Then they simplify the end expression to obtain the resulting expression.
- Automatic differentiation => tensorflow gradient optimizer
Automatic differentiation manipulates blocks of computer programs. A differentiator has the rules for taking the derivative of each element of a program (when you define any op in core TF, you need to register a gradient for this op). It also uses chain rule to break complex expressions into simpler ones. Here is a good example how it works in real TF programs with some explanation. tensorflow gradient explainfor example below tensorflow code shows us simple policy gradient implementation

Tensorflow just need J function and optimizer function executes the gradient like below

Neural Network
Neural network
The core of our new agent is a neural network that decides what to do in a given situation. There are two sets of outputs – the policy itself and the value function.
Neural network architecture
It is defined very easily with Keras:
l_input = Input( batch_shape=(None, NUM_STATE) )
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
The policy output goes through softmax activation to make it correct probability distribution. The ouput for value function is linear, as we need all values to be possible.

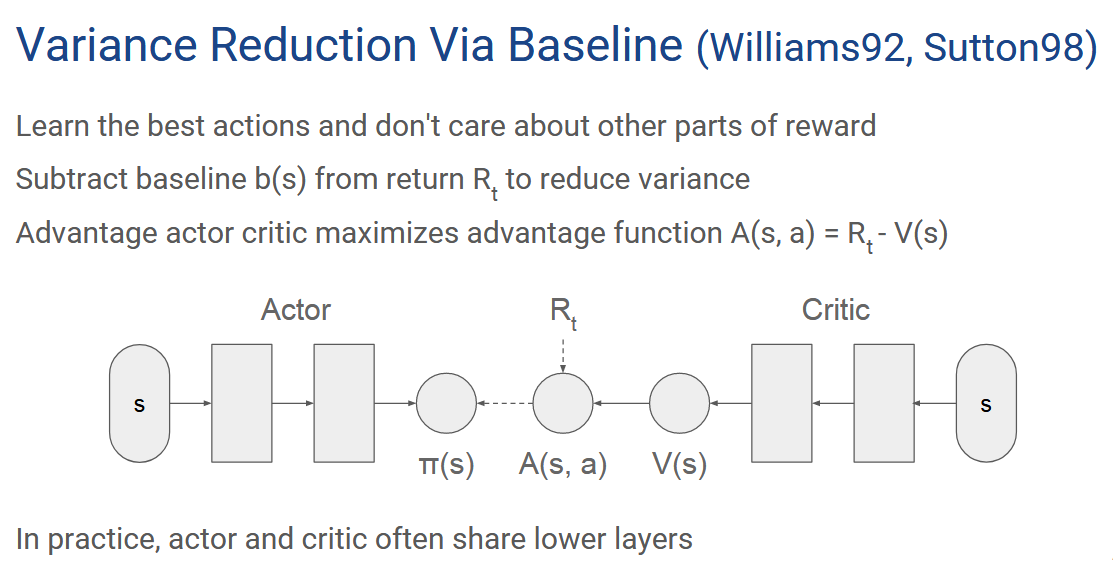
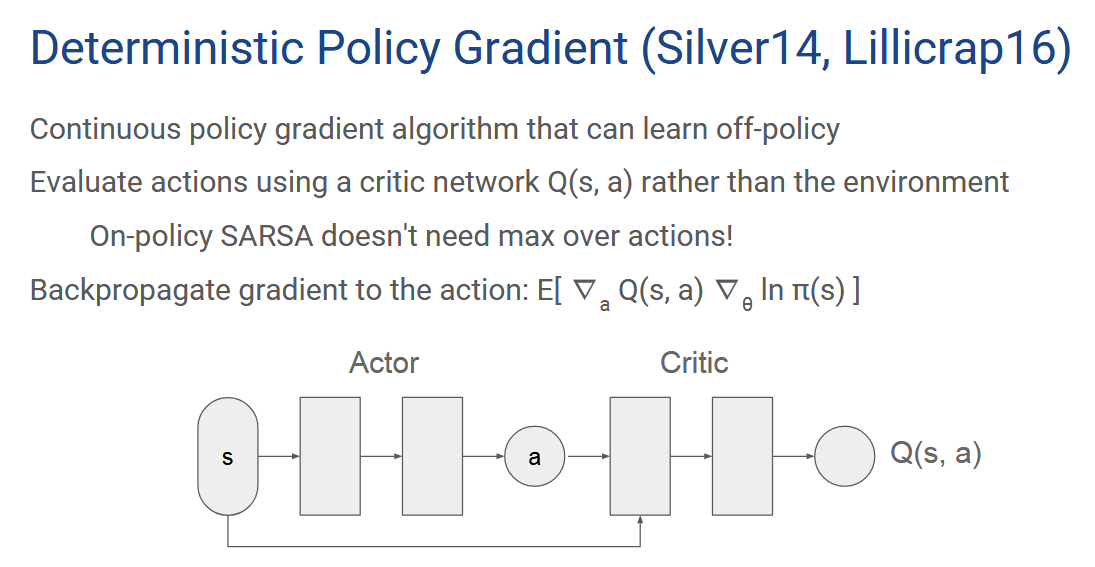
reference links
tensorflow differentiation explain
stanford policy gradient tutorial
policy gradient tensorflow impl
Implementing Deep Reinforcement Learning Models with Tensorflow + OpenAI Gym