Advantage Actor-Critic Example
Understand Actor-Critic (AC) algorithms
- Learned Value Function
- Learned Policy
- this example uses Advantage Actor(policy weight)-Critic(Value Weight) Algorithm
Monte Carlo Policy Gradient sill has high variance so critic estimates the action-value function
- critic updates action-value function parameters w
- actor updates policy parameter
tensorflow main code
- initialize tensorflow graph
- create session
- run actor_critic function
# reset tensor flow graph
tf.reset_default_graph()
# non-trainable, global step tensorflow variable
global_step = tf.Variable(0, name="global_step", trainable=False)
# create Policy Estimator => actor
policy_estimator = PolicyEstimator()
# create Value Estimator => critic
value_estimator = ValueEstimator()
with tf.Session() as sess:
# initialize tensorflow session variables
sess.run(tf.initialize_all_variables())
# Note, due to randomness in the policy the number of episodes
# you need to learn a good policy may vary. ~300 seemed to work well for me.
stats = actor_critic(env, policy_estimator, value_estimator, 300)
def actor_critic(env, estimator_policy, estimator_value, num_episodes, discount_factor=1.0):
"""
Actor Critic Algorithm. Optimizes the policy
function approximator using policy gradient.
Args:
env: OpenAI environment. => class CliffWalkingEnv
estimator_policy: Policy Function to be optimized ,class PolicyEstimator
estimator_value: Value function approximator, used as a critic, class ValueEstimator
num_episodes: Number of episodes to run for
discount_factor: Time-discount factor
Returns:
An EpisodeStats object with two numpy arrays for episode_lengths
and episode_rewards.
"""
# Keeps track of useful statistics
stats = plotting.EpisodeStats(
episode_lengths=np.zeros(num_episodes),
episode_rewards=np.zeros(num_episodes))
'''
>>> # collections.namedtuple Basic example
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(11, y=22) # instantiate with positional or keyword arguments
>>> p[0] + p[1] # indexable like the plain tuple (11, 22)
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> p # readable __repr__ with a name=value style
Point(x=11, y=22)
'''
Transition = collections.namedtuple("Transition", ["state", "action", "reward",
"next_state", "done"])
'''
t = Transition(state=state, action=action, reward=reward, next_state=next_state,
done=done)
t.state, t.action
'''
# for example, num_episodes = 300
for i_episode in range(num_episodes):
# Reset the environment and pick the fisrst action
state = env.reset() # class CliffWalkingEnv
episode = []
# One step in the environment
# itertools example http://jmduke.com/posts/a-gentle-introduction-to-itertools/
# itertools.count() from 0 to unlimited count, if done is true, this loop stops
for t in itertools.count():
# Take a step
action_probs = estimator_policy.predict(state)
action = np.random.choice(np.arange(len(action_probs)), p=action_probs)
next_state, reward, done, _ = env.step(action)
# Keep track of the transition
episode.append(Transition(
state=state, action=action, reward=reward, next_state=next_state, done=done))
# Update statistics
stats.episode_rewards[i_episode] += reward
stats.episode_lengths[i_episode] = t
# Calculate TD Target
value_next = estimator_value.predict(next_state)
td_target = reward + discount_factor * value_next
td_error = td_target - estimator_value.predict(state)
# Update the value estimator
estimator_value.update(state, td_target)
# Update the policy estimator
# using the td error as our advantage estimate
estimator_policy.update(state, td_error, action)
# Print out which step we're on, useful for debugging.
print("\rStep {} @ Episode {}/{} ({})".format(
t, i_episode + 1, num_episodes, stats.episode_rewards[i_episode - 1]), end="")
if done:
break
state = next_state
return stats
itertools tf.one_hot tf.placeholder tf.squeeze
class PolicyEstimator():
"""
Policy Function approximator.
"""
def __init__():
# state 4 X 12
# action UP=0 RIGHT=1 DOWN=2 LEFT=3
# target is td_error => td_target - estimator_value.predict(state)
self.state = tf.placeholder(tf.int32, [], "state")
self.action = tf.placeholder(dtype=tf.int32, name="action")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# This is just table lookup estimator
# openai gym class CliffWalkingEnv(discrete.DiscreteEnv)
# refer to the below code self.observation_space = spaces.Discrete(self.nS)
# env.observation_space.n => 4 X 12 = 48
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
# state_one_hot => (48,)
# env.action_space.n => 4 UP=0 RIGHT=1 DOWN=2 LEFT=3
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=env.action_space.n,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
# selected action from softmax layer
# softmax(self.output_layer) is softmax policy for discrete actions
# refer to below softmax policy figure
# output_layer => (1,4)
# softmax => (1,4)
# squeeze => (4,)
# action_probs = (4,)
# picked_action_prob : gather ()-> float32
self.action_probs = tf.squeeze(tf.nn.softmax(self.output_layer))
self.picked_action_prob = tf.gather(self.action_probs, self.action)
# Loss and train op
self.loss = -tf.log(self.picked_action_prob) * self.target
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
# sess or use default tensorflow session
sess = sess or tf.get_default_session()
# run self.action_prob with {state}
return sess.run(self.action_probs, { self.state: state })
def update(self, state, target, action, sess=None):
sess = sess or tf.get_default_session()
feed_dict = { self.state: state, self.target: target, self.action: action }
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
class ValueEstimator():
"""
Value Function approximator.
"""
def __init__(self, learning_rate=0.1, scope="value_estimator"):
with tf.variable_scope(scope):
self.state = tf.placeholder(tf.int32, [], "state")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# This is just table lookup estimator
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=1,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
self.value_estimate = tf.squeeze(self.output_layer)
self.loss = tf.squared_difference(self.value_estimate, self.target)
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
sess = sess or tf.get_default_session()
return sess.run(self.value_estimate, { self.state: state })
def update(self, state, target, sess=None):
sess = sess or tf.get_default_session()
feed_dict = { self.state: state, self.target: target }
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
below code snippet is actor-critic algorithm flow
- loop in each episode
- current state, take current action, run environment
- take next state, next reward, game done signal from environment
- calculate estimated value of next state
- calculate td_target = reward + discount_factor* next estimated value
- calculate td_error = td_target - current estimated value
- update state value with current state and td_target
- update policy weight with current state, td_error and current action
- loop goes until game is done
- state update with next state

# Take a step
action_probs = estimator_policy.predict(state)
action = np.random.choice(np.arange(len(action_probs)), p=action_probs)
next_state, reward, done, _ = env.step(action)
action_probs is estimated action lists of current state. action_prob is an output from softmax probabilities regarding 4 actions(self.action_probs = tf.squeeze(tf.nn.softmax(self.output_layer)). And action is the selected value in action lists
env.step(action) generates next_state,next reward, done signal
# Calculate TD Target
value_next = estimator_value.predict(next_state)
td_target = reward + discount_factor * value_next
# td_target - current state's value => td_error
td_error = td_target - estimator_value.predict(state)
# Update the value estimator
estimator_value.update(state, td_target)
# ValueEstimator()
# self.value_estimate = tf.squeeze(self.output_layer)
# self.loss = tf.squared_difference(self.value_estimate, self.target)
# Update the policy estimator
# using the td error as our advantage estimate
estimator_policy.update(state, td_error, action)
# PolicyEstimator()
# softmax output : picked_action_prob, target: td_error
# self.loss = -tf.log(self.picked_action_prob) * self.target
Summarize Actor-Critic Algo
Critic minimized the this loss function: (estimated value of current state from DNN - td_target)
Actor estimates the td_error plus current estimated action from policy network
Explain Critic Algo
estimator_value.update(state,td_target) runs critic algorithm, self.loss tensor in update function related with tf.squared_difference(self.value_estimate, self.target),self.value_estimate is the current value from current state and this is
in the TD(0) Critic Algo. Critic can esitmate value function
Basic TD(0) Critic Algo is below formula
td_target is
and self.target means this td_target.
so critic is updated to minimize MSE with regard to target given by MC or TD(0)
=>tf.squared_difference(self.value_estimate, self.target)
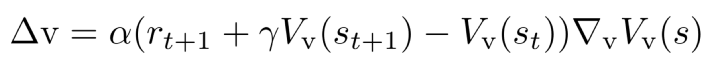
Explain Actor Algo
the policy gradient can also be estimated as follows:
Actor-Critic policy gradient uses the one-step TD error
, from the code -tf.log(self.picked_action_prob) * self.target where self.target is td_error and self.picked_action_prob is softmax output.
Q: how to explain about
in score function
(softmax policy : discrete actions)

Estimating the Advantage Actor-Critic



1
2
self.action_probs = tf.squeeze(tf.nn.softmax(self.output_layer))
self.picked_action_prob = tf.gather(self.action_probs, self.action)
 —
—
Example cliff-walk with Actor-Critic algo
The cliff-walking task. The results are from a single run, but smoothed by averaging the reward sums from 10 successive episodes.
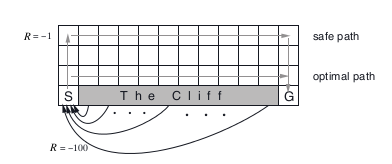
from lib.envs.cliff_walking import CliffWalkingEnv
#this example test cliff walking
from lib import plotting
#create openai gym
env = CliffWalkingEnv()
# CliffWalking Environment
class CliffWalkingEnv(discrete.DiscreteEnv):
metadata = {'render.modes': ['human', 'ansi']}
def __init__(self):
# maze size is 4 X 12 matrix
self.shape = (4, 12)
# np.prod => Return the product of array elements over a given axis.
nS = np.prod(self.shape) # nS => 4*12
nA = 4
# Cliff Location
self._cliff = np.zeros(self.shape, dtype=np.bool)
self._cliff[3, 1:-1] = True # cliff postion
# Calculate transition probabilities
P = {}
# nS = 4*12 = 48
for s in range(nS):
# Converts a flat index or array of flat indices
# into a tuple of coordinate arrays.
# s = 47 , temp_shape = (4 ,12)
# position = np.unravel_index(s, temp_shape)
# position = (3 ,11)
position = np.unravel_index(s, self.shape)
P[s] = { a : [] for a in range(nA) }
P[s][UP] = self._calculate_transition_prob(position, [-1, 0])
P[s][RIGHT] = self._calculate_transition_prob(position, [0, 1])
P[s][DOWN] = self._calculate_transition_prob(position, [1, 0])
P[s][LEFT] = self._calculate_transition_prob(position, [0, -1])
# We always start in state (3, 0)
isd = np.zeros(nS)
isd[np.ravel_multi_index((3,0), self.shape)] = 1.0
super(CliffWalkingEnv, self).__init__(nS, nA, P, isd)
env._cliff
>>>
array([[False, False, False, False, False, False, False, False, False,
False, False, False],
[False, False, False, False, False, False, False, False, False,
False, False, False],
[False, False, False, False, False, False, False, False, False,
False, False, False],
[False, True, True, True, True, True, True, True, True,
True, True, False]])
env.P[0] # 0:UP,1:RIGHT,2:DOWN,3:LEFT :{(1.0,new_state(0~47),reward(-1 or -100),is_done)}
>>>
{0: [(1.0, 0, -1.0, False)],
1: [(1.0, 1, -1.0, False)],
2: [(1.0, 12, -1.0, False)],
3: [(1.0, 0, -1.0, False)]}
def _calculate_transition_prob(self, current, delta):
new_position = np.array(current) + np.array(delta)
new_position = self._limit_coordinates(new_position).astype(int)
new_state = np.ravel_multi_index(tuple(new_position), self.shape)
reward = -100.0 if self._cliff[tuple(new_position)] else -1.0
is_done = self._cliff[tuple(new_position)] or (tuple(new_position) == (3,11))
return [(1.0, new_state, reward, is_done)]
# current =(0,0), delta =[-1,0]
new_position = np.array(current) + np.array(delta)
>> new_position [-1,0]
# check shape limit size (4,12)
new_position = self._limit_coordinates(new_position).astype(int)
>> new_position [0,0]
print((tuple(new_position)))
>>(0,0)
# self.shape = (4,12), tuple(new_position) = (0,0)
new_state = np.ravel_multi_index(tuple(new_position), self.shape)
>> 0 # new_state is index of (4*12) array (0,0)->0 , (1,0) -> 12
reward = -100.0 if self._cliff[tuple(new_position)] else -1.0 # reward -1 or -100(cliff)
# is_done is true if position is cliff or arrives goal(3,11)
is_done = self._cliff[tuple(new_position)] or (tuple(new_position) == (3,11))
openAI gym DiscreteEnv super(CliffWalkingEnv, self).init(nS, nA, P, isd) initializes below open ai environment
class DiscreteEnv(Env):
"""
Has the following members
- nS: number of states
- nA: number of actions
- P: transitions (*)
- isd: initial state distribution (**)
(*) dictionary dict of dicts of lists, where
P[s][a] == [(probability, nextstate, reward, done), ...]
(**) list or array of length nS
"""
def __init__(self, nS, nA, P, isd):
self.P = P
self.isd = isd
self.lastaction=None # for rendering
self.nS = nS
self.nA = nA
self.action_space = spaces.Discrete(self.nA)
self.observation_space = spaces.Discrete(self.nS)
#episode plotting
#episode size 300
print(len(stats.episode_lengths))
>> 300
cumsum = np.cumsum(stats.episode_lengths)
print(stats.episode_lengths[:10])
print(cumsum[:10])
>>[ 3. 1. 8. 0. 1. 31. 4. 6. 2. 33.]
>>[ 3. 4. 12. 12. 13. 44. 48. 54. 56. 89.]