Deep Reinforcement : Imitation Learning
Deep Reinforcement : Imitation Learning
Deep Reinforcement : Imitation Learning
- Is Behavior Cloning/Imitation Learning as Supervised Learning possible?
- Answer is NO
-
Answer is No to clone behavior of animal or human but worked well with autonomous vehicle paper

- suggesting the possibility of a novel adaptive autonomous navigation system capable of tailoring its processing to the condition at hand

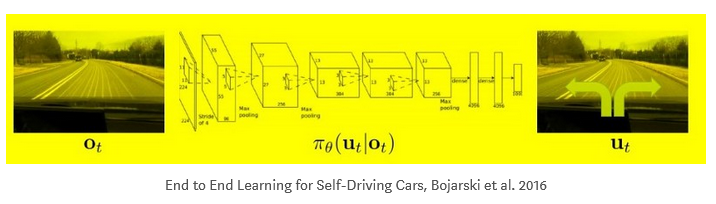
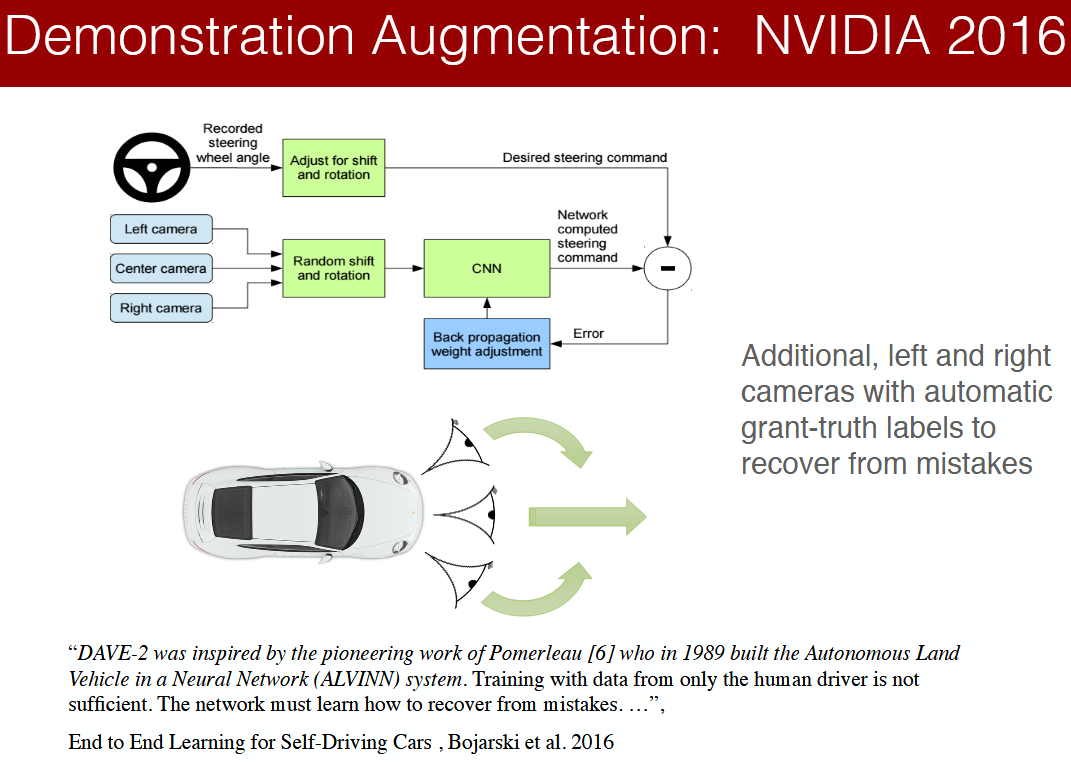
- DARPA used ALVINN model and later NVIDIA(Bojarski et al.’ 16, NVIDIA) model(CNNs) shown
cloning is possible to learn the entire task of lane and road following without manual decomposition into road or lane marking detection, semantic abstraction, path planning and control -
Model was able to learn meaningful road features from a very sparse training signal(steering alone)
- Behavior Learning or imitation learning is successful when the trajectory distribution(policy with state action) of agent or learner matches the expert or trainer(GANs- Generative Adversarial Networks, Goodfellow et al. 2014)
-
Challenge in cloning is actions along trajectory is interdependent(상호의존)
- We directly supervise learning to map states to actions by demonstrating trajectories
- By showing the ways to handle the neglect of action interdependence
- Learning latent rewards or goals is indirect(Inverse Reinforcement Learning)
Who are experts here?
-
Experts are human, Optimal or near Optimal Planners/Controllers with assumptions like expert trajectories are i.i.d and training distribution matches test data distributions

Data Set Aggregation
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
Abstract
- In this paper, we propose a new iterative algorithm, which trains a stationary deterministic policy, that can be seen as a no regret algorithm in an online learning setting
- We show that any such no regret algorithm must find a policy with good performance under the distribution of observations
- We demonstrate that this new approach outperforms previous approaches on two challenging imitation learning problems and a benchmark sequence labeling problem
Introduction
- For instance, most robotic systems must be able to predict/make a sequence of actions given a sequence of observations over time
- Imitation Learning ,where expert demonstrations of good behavior are used to learn a controller, have proven very useful in practice and have led to state of art performance
- A typical approach to imitation learning has still problem
- the learner’s prediction affects future input observation/states during execution of the learned policy, this violate the crucial i.i.d
- Intuitively this is because as soon as the learner makes a mistake, it may en-counter completely different observations than those under expert demonstration, leading to a compounding of errors
- We propose a new meta-algorithm for imitation learning which learns a stationary deterministic policy guaranteed to perform well under its induced distribution of states (number of mistakes/costs that grows linearly in T and classification cost)
- Our approach is simple to implement, has no free parameters except the supervised learning algorithm sub-routine, and requires a number of iterations that scales nearly linearly with the effective hori-zon of the problem. It naturally handles continuous as well as discrete predictions.
- Our approach is closely related to no regret online learning algorithm
- We begin by establishing our notation and setting, discuss related work, and then present the DAGGER(Dataset Ag-gregation) method. We analyze this approach using a no-regret and a reduction approach
- We demonstrate DAGGER is scalable and outperforms previous approaches in practice on two challenging imitation learning problems:
Preliminaries
- For any policy π, we let denote
 the
distribution of states at time t if the learner executed policy π from time step 1 to t−1
the
distribution of states at time t if the learner executed policy π from time step 1 to t−1 -
Furthermore, we denote
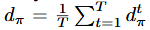 the average distribution of states if we follow policy π
for T steps
the average distribution of states if we follow policy π
for T steps - Given a state s, we de-note C(s,a) the expected immediate cost of performing action
a in state s for the task we are considering and denote
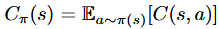 the expected immediate cost of π in s
the expected immediate cost of π in s - We assume C is bounded in [0,1]
- The total cost of executing policy π for T-steps (i.e., the cost-to-go) is denoted
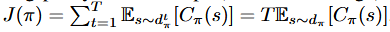
- Instead, we observe expert demonstrations and seek to bound J(π) for any cost function C based on how well π mimics the expert’s policy π∗
- Denote
 the observed surrogate loss
function we minimize instead of C
the observed surrogate loss
function we minimize instead of C - Our goal is to find a policy ˆπ which minimizes the observed surrogate loss under its induced
distribution of state

Supervised Approach to Imitation
- The traditional approach to imitation learning ignores the change in distribution and simply trains a policy π that performs well under the distribution of states encountered by the expert dπ∗
- This can be achieved using any standard supervised learning algorithm. It finds the policy
ˆπsup


Hence the traditional supervised learning approach has poor performance guarantees due to the quadratic growth in T
Forward Training
- The forward training algorithm introduced by Ross and Bagnell (2010) trains a non-stationary policy
- Hence the forward algorithm guarantees that the expected loss under the distribution of states induced by the learned policy matches the average loss during training, and hence improves performance
DATASET AGGREGATION
- We now present DAGGER(Dataset Aggregation), an iterative algorithm that trains a deterministic policy that achieves good performance guarantees under its induced distribution of states


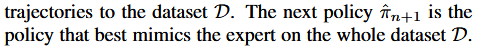

- In other words, DAGGER proceeds by collecting a dataset at each iteration under the current policy and trains the next policy under the aggregate of all collected datasets


Imitation Learning Lecture Summary


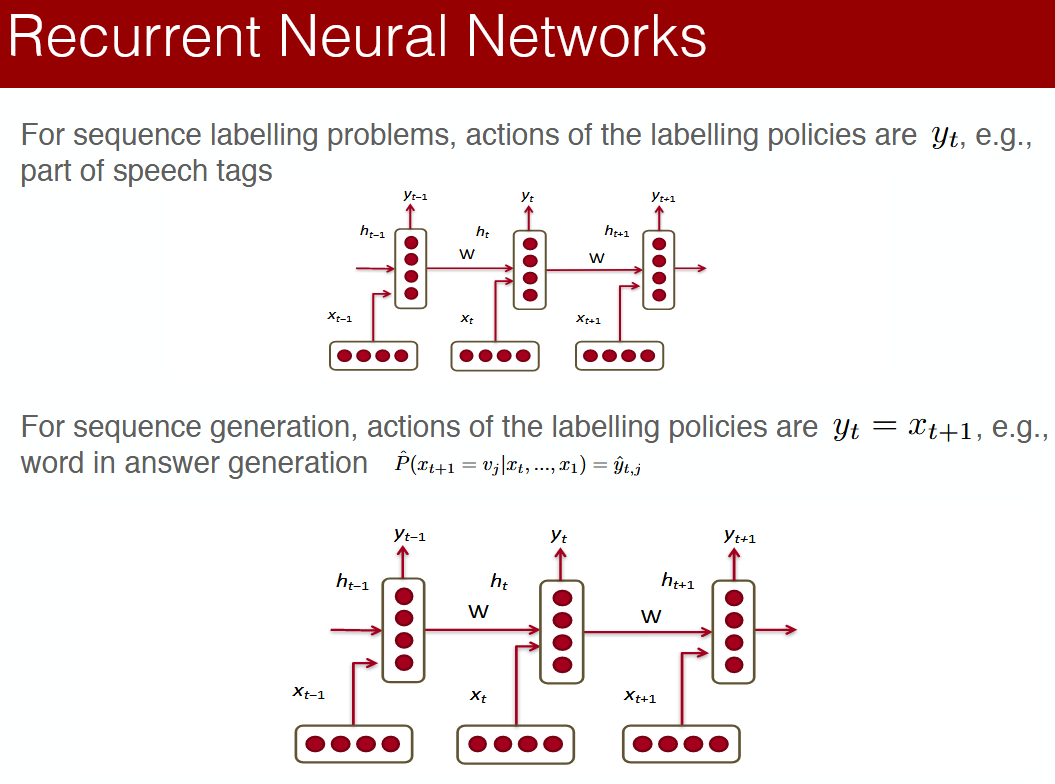



Augmentation
- Augmentation helps us extract as much information from data as possible We will generate additional data using the following data augmentation techniques
- Augmentation is a technique of manipulating the incoming training data to generate more instances of training data
-
This technique has been used to develop powerful classifiers with little data keras image classification
However, augmentation is very specific to the objective of the neural network