Karpathy Policy Gradient Analysis
Introduction
RL research Area
- ATARI games
- Alpha Go
- robots learning how to perform complex manipulation tasks
- etc
RL education
- Richard Sutton
- David Silver course
- John Schulmann’s lectures
Four separate factors about AI
- Compute(the obvious one: Moore’s Law,GPU,ASICs)
- Data(in a nice form)
- Algorithms (research and ideas, CNN,LSTM)
- Infrastructure(software -Linux,ROS,TCP/IP,Git,AWS,Tensorflow,etc)
Short history about ATARI and AlexNet , Alpha Go Development
- 2012 AlexNet envolving from 1990’s ConvNets
- 2013 ATARI Deep Q learning paper is a standard implementation of Q learning with function approximation in sutton’s book
- AlphaGo uses policy gradients with Monte Carlo Tree Search(MCTS)
Policy Gradients Algorithm in RL
- PG is preferred because it is end to end: there’s an explicit policy
- A principled approach that directly optimizes the expected reward
Pong Game under PG
- an image frame(210 X 160 X 3) byte array(integers from 0 to 255 giving pixel values)
- the paddle UP/DOWN(binary choice)
- the game simulator gives us reward after executing the action
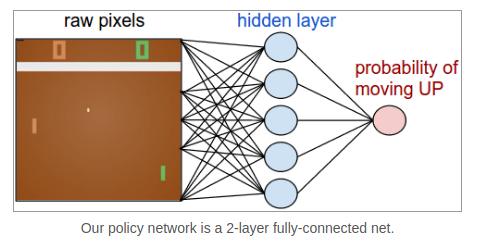
Policy Network
- The network takes the state of the game and decides the action(UP/DOWN)
- This is a stochastic policy
- python implementation of above policy network
h = np.dot(W1, x) # compute hidden layer neuron activations h[h<0] = 0 # ReLU nonlinearity: threshold at zero logp = np.dot(W2, h) # compute log probability of going up p = 1.0 / (1.0 + np.exp(-logp)) # sigmoid function (gives probability of going up) - sigmoid non-linearity makes output probability to the range [0,1]
- W1 detects various game scenarios
- W2 decides actions(UP/DOWN)
- the only problem is to find W1 and W2
It sounds kind of impossible
- 100,800(210x160x3) and forward our policy network(W1 and W2)
- we could repeat this training process until we get any non-zero reward -> credit assignment problem
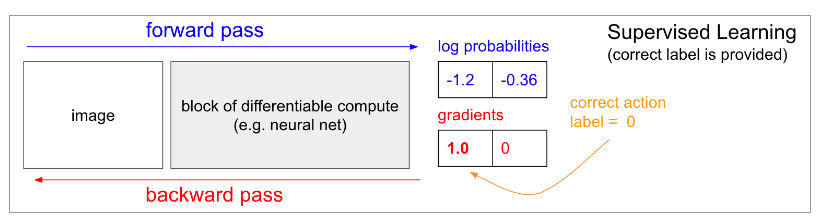
Supervised Learning
- In ordinary supervised learning we would feed an image to the network and get some probabilities(two classes UP and DOWN)
- out network would now be slightly more likely to predict UP when it sees a very similar image in the future
- we need correct label(UP/DOWN)
Policy Gradients
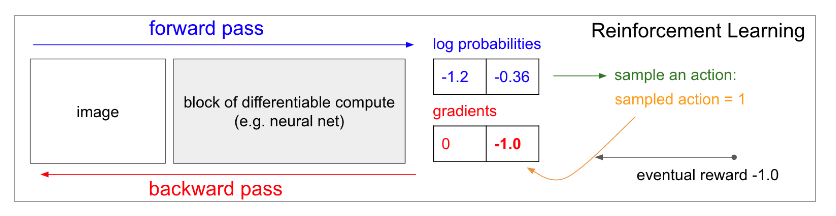
- If we don’t have correct labels, what do we do?
- The answer is Policy Gradients solution
- policy network calculated probabilities of going UP as 30%(logprob -1.2) and DOWN as 70%(logprob -0.36) and select the DOWN action
- Finally, we get -1 reward(+1 if we won or -1 if we lost)
- so backpropagation fills the network params which makes the same input in the future not to take DOWN action
Training protocol
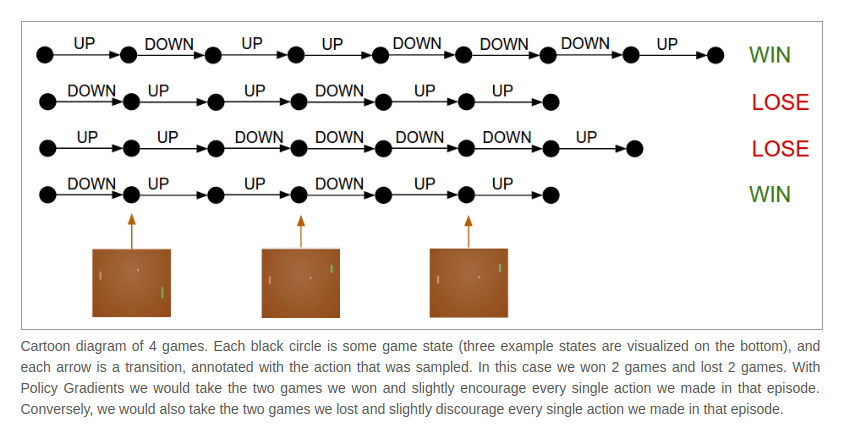
- how the training works in detail
- the policy network with W1,W2 and play 100 games
- 200 frames and 20,000 decisions for each game
- All that remains now is to label every decision as good or bad
- won 12 games and lost 88 games
- 200 frame * 12 won games = 2400 decisions -> positive updates
- +1.0 in the gradients -> doing backprop -> parameter updates encouraging the action
- 200 frame * 88 lost games = 17600 decisions -> negative updates
Deriving Policy Gradients
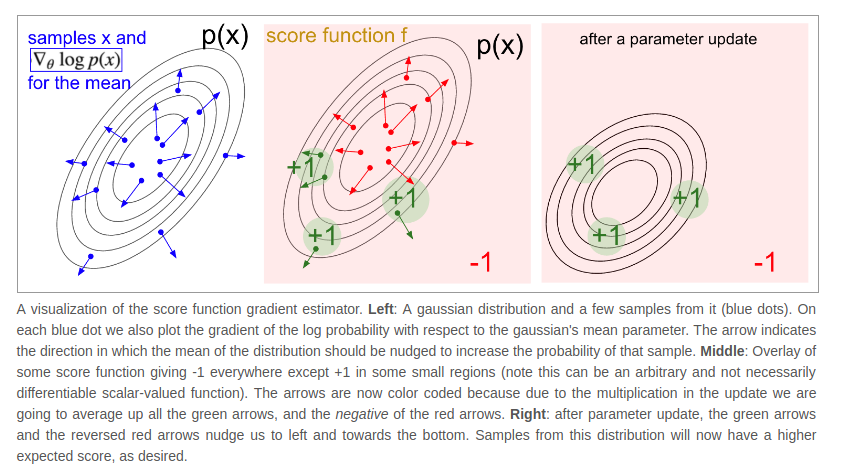
- Policy gradients are a special case of a more general score function gradient esimator
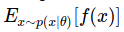 :
the expectation of some scalar values score function
:
the expectation of some scalar values score function 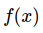 under some probability distribution
under some probability distribution 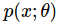
- score function become our reward function or advantage function
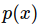 is our policy network
is our policy network-
is a model for
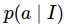 , giving a distribution over actions for any Image I
, giving a distribution over actions for any Image I -
What we must do is how to shift the distribution(through parameters
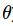 ) to increase the scores of its samples
) to increase the scores of its samples -
how do we change the network’s parameters so that action samples get higher rewards

- distribution have some samples x(this could be a gaussian)
- For each sample we can evaluate the score function which takes the sample and gives us some scalar-valued score
- This equation is telling us how we shift the distribution(through its parameter )
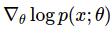 is a vector
is a vector
- the gradient gives us the direction in the parameter space
- if we were to nudge in the direction of we would see the new probability
Non-differentiable computation in Neural Networks
- introduced and popularized by Recurrent Models of Visual Attention under the name hard attention
- model processes an image with a sequence of low-resolution foveal glances
- at every iteration RNN receives a small piece of the image and sample a location to look at next
- RNN look at position(5,30) then decide to look at (24,50) next
- this operation is non-differentiable because we don’t know what would have happened if we sampled a different location
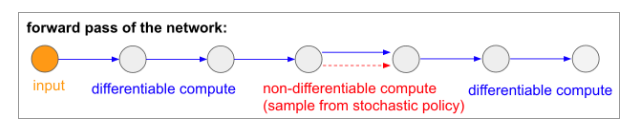
- non-differentiable computation(red) can’t be backprop through
- during training we will produce several samples and then we’ll encourage samples that eventually led to good outcomes
- the parameters involved in the blue arrows are updated with backprop as usual
- the parameters involved in the red arrows are updated independently using policy gradients which encouraging samples that led to low loss
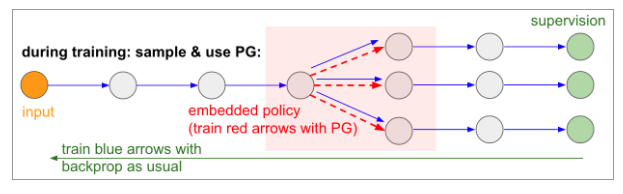
Reference sites
deterministic policy gradients from silver, deepmind
trajectory optimization, robot teleoperation from Karpathy policy gradient blog