Conditional Imitation Learning CARLA
Conditional Imitation Learning at CARLA
Conditional Imitation Learning at CARLA
End-to-end Driving via Conditional Imitation Learning (Paper)
End-to-end Driving via Conditional Imitation Learning (Paper)

Abstract
- Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles
- However, driving policies trained via imitation learning cannot be controlled at test time
- We propose to condition imitation learning on high-level command input
Introduction
- Imitation learning can be used to train a model that maps perceptual inputs to control commands
- for example, mapping camera images to steering and acceleration
- lane following ,off-road obstacle avoidance
- However, these systems have characteristic limitations
- NVIDIA Implementation
- For example, the network trained by Bojarski et al. [4] was given control over
lane and road following only. When a lane change or a turn from one road to another were required, the human driver had to take control [4]
- For example, the network trained by Bojarski et al. [4] was given control over
- Why has imitation learning not scaled up to fully autonomous urban driving?
- One limitation is in the assumption that the optimal action can be inferred from the perceptual input alone
- when a car approaches an intersection, the camera input is not sufficient to predict whether the car should turn left, right, or go straight
- In this paper, we address this challenge with conditional imitation learning
- **At training time, the model is given not only the perceptual input and the
control signal, but also a representation of the expert’s intention. ** - At test time,the network can be given corresponding commands, which resolve the ambiguity in the perceptuomotor mapping
- The trained network is thus freed from the task of planning and can devote its representational capacity to driving
- **At training time, the model is given not only the perceptual input and the
- We evaluate the presented approach in realistic simulations of urban driving and
on a 1/5 scale robotic truck
Related work
- we develop a command-conditional formulation that enables the application of
imitation learning to more complex urban driving. - Another difference is that we learn to control not only steering but also acceleration and braking, enabling the model to assume full control of the car
- In reinforcement learning, hierarchical approaches aim to construct multiple
levels of temporally extended sub-policies - Hierarchical approaches have also been combined with deep learning and applied to raw sensory input
- In these works, the main aim is to learn purely from experience and discover hierarchical structure automatically
- In contrast, we focus on imitation learning, and we provide additional information on the expert’s intentions during demonstration
- This formulation makes the learning problem more tractable and yields a human-controllable policy
- Parameterized goals have been used to train motion controllers in robotics
- Our work shares the idea of training a conditional controller, but differs in the
model architecture,the application domain (vision-based autonomous driving), and the learning method (conditional imitation learning) - On the opposite side are end-to-end approaches that train function approximators
to map sensory input to control commands - we limit commands to a predefined vocabulary such as “turn right at the next
intersection”, “turn left at the next intersection”, and “keep straight”.
Conditional Imitation Learning



-

-
However, in more complex scenarios the assumption that the mapping of observations to actions is a function breaks down


- these turn signals can be used as commands in our formulation
- These test-time commands can come from a human user or a planning module
- In urban driving, a typical command would be “turn right at the next
intersection”,which can be provided by a navigation system or a passenger 
Methodology
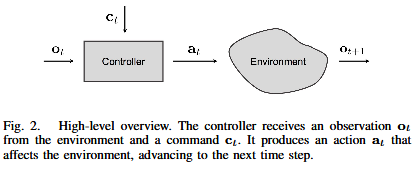
observation : Image measurement : acceleration command : human interface
1) Network Architecture
-

-
In our driving experiments, the action space is continuous and
two-dimensional: steering angle and acceleration. The acceleration can be negative, which corresponds to braking or driving backwards. The command c is a categorical variable represented by a one-hot vector -
We study two approaches to incorporating the command c into the network.
The first architecture is illustrated in Figure 3(a). The network takes the command as an input, alongside the image and the measurements. 

-
which can lead to suboptimal performance in practice
- We therefore designed an alternative architecture, shown in Figure 3(b)
-

-

- The command c acts as a switch that selects which branch is used at any
given time. The output of the network is thus 
2) Network Details
-

- The image module consists of 8 convolutional and 2 fully connected layers. The
convolution kernel size is 5 in the first layer and 3 in the following layers. The
first, third,and fifth convolutional layers have a stride of 2. The number
of channels increases from 32 in the first convolutional layer to 256 in the
last. Fully-connected layers contain 512 units each. -
We used ReLU nonlinearities after all hidden layers, performed batch normalization after convolutional layers, applied 50% dropout after fully-connected hidden
layers, and used 20% dropout after convolutional layers 
- All models were trained using the Adam solver [16] with minibatches of 120 samples and an initial learning rate of 0.0002
3) Training Data Distribution
- When performing imitation learning, a key decision is how to collect the training data
- The simplest solution is to collect trajectories from natural demonstrations of an
expert performing the task. This typically leads to unstable policies, since a model that is only trained on expert trajectories may not learn to recover from disturbance or drift -
In DAgger [29], the expert remains in the loop during the training of the controller: the controller is iteratively tested and samples from the obtained trajectories are re-labeled by the expert
- In this paper we adopt a three-camera setup inspired by Bojarski
4) Data Augmentation
- We found data augmentation to be crucial for good gen-eralization
- Transformations include change in contrast, brightness, and tone, as well as addition of Gaussian blur, Gaussian noise, salt-and-pepper noise, and region dropout
System Setup
-
We evaluated the presented approach in a simulated urban environment and on a
physical system – a 1/5 scale truck. In both cases, the observations
(images) are recorded by one central camera and two lateral cameras
rotated by 30 degrees with respect to the center. -
The recorded control signal is two-dimensional: steering angle and
acceleration -
During training data collection, when approaching an intersection the
driver uses buttons on a physical steering wheel (when driving in simulation) or on the remote control (when operating the physical truck) to indicate the command corresponding to the intended course of action. The driver indicates the
command when the intended action becomes clear, akin to turn indicators in cars or navigation instructions provided by mapping applications. This way we collect realistic data that reflects how a higher level planner or a human could direct the system
1) Simulated Environment
-
We use CARLA [10],. CARLA is an open-source simulator implemented using Unreal Engine 4.

- In order to collect training data, a human driver is presented with a
first-person view of the environment (center camera) at a resolution of 800×600 pixels. The driver controls the simulated vehicle using a physical steering wheel and pedals, and provides command input using buttons on the steering wheel. The driver keeps the car at a speed below 60 km/h and strives to avoid collisions with cars and pedestrians, but ignores traffic lights and stop signs. We record images from the three simulated cameras, along with other measurements such as speed and the position of the car. The images are cropped to remove part of the sky. CARLA also provides extra
information such as distance travelled, collisions, and the occurrence of
infractions such as drift onto the opposite lane or the sidewalk. This
information is used in evaluating different controller
2) Physical System
- The setup of the physical system is shown in Figure 6. We equipped an
off-the-shelf 1/5 scale truck (Traxxas Maxx) with an embedded computer (Nvidia TX2), three low-cost webcams, a flight controller (Holybro Pixhawk) running the APMRover firmware, and supporting electronics. 
Experiments
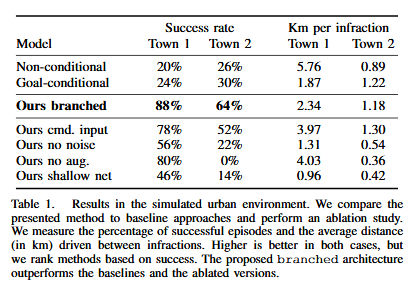
1) Simulated Environment
- The use of the CARLA simulator enables running the evaluation in an episodic
setup