DDPG Actor-Critic Policy Gradient in Tensorflow
Intorduction
After Deep Q-Network became a hit,people realized that deep learning methods could be used to solve a high-dimensional problems. one of challenges in reinforcement learning is how to deal with continuous action spaces. for example,robotic control, stock prediction
Deepmind has devised a solid algorithm for solving the continuous action space problem. policy gradient actor-critic algorithm called Deep Deterministic Policy Gradients(DDPG) that is off-policy and model-free that were introduced along with Deep Q-Networks.
Example
In this blog, I’m introducing how to implement this algorithm using Tensorflow and tflearn and then evaluate it with OpenAI Gym on the pendulum environment.
Policy-Gradient Methods
Policy Gradient optimizes a policy end to end by computing noisy estimates of the gradient of the expected reward of the policy and then updating the policy in the gradient direction.
PG methods have assumed a stochastic policy 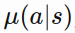 , which gives a probability distribution over actions. this algorithms sees lots of training examples of high rewards from the good actions and negative rewards from bad actions.
then it can increase the probability of the good actions.
, which gives a probability distribution over actions. this algorithms sees lots of training examples of high rewards from the good actions and negative rewards from bad actions.
then it can increase the probability of the good actions.
Actor-Critic Algorithms
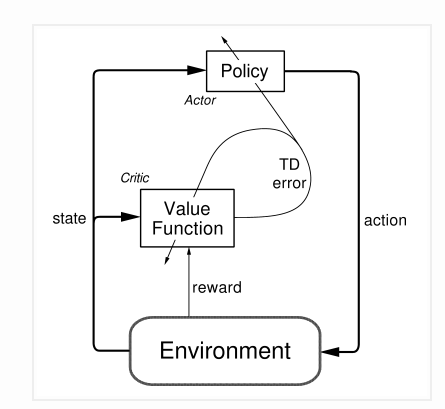
The policy function is known as the actor, and the value function is referred to as the critic. The actor produces an action given the current state of the environment, and the critic produces a TD error signal given the state and resultant reward. If the critic is estimating the action-value function, it will also need the output of the actor. critic uses next state value(td target) in which is generated from current action . The output of the critic drives learning in both the actor and the critic.
Off-policy Vs. On-Policy
RL algorithms which are chracterized as off-policy generally employ a separate behavior policy. the behavior policy is used to simulate a trajectories. A key benefit of this separation is that the behavior policy can operate by sampling all actions, whereas the estimation policy can be deterministic(e greedy). On-policy algorithms directly use the policy that is being estimated to sample trajectories during the training.
Model-free Algorithms
Model-free RL makes no effort to learn the underlying dynamics that govern how an agent interacts with the environments. Model-free algorithms directly estimate the optimal policy or value function through algorithms such as policy interation or value iteration. This is much more computationally efficient. But Model-free methods generally require a large number of training examples.
DDPG(Deep Deterministic Policy Gradient)
policy gradient actor-critic DDPG is a policy gradient algorithm that uses a stochastic behavior policy for good exploration but estimates a deterministic target policy. Policy gradient algorithms utilize a form of policy iteration;they evaluate the policy, and then follow the policy gradient to maximize performance.
- DDPG is
- off-policy
- uses a deterministic target policy
- actor-critic algorithms
- primarily uses two neural network(one for actor and one for critic)
- these networks compute action prediction for the current state
- generate TD error each time step
- the input of the action network is the current state and the output is a single real value representing an action chosen from a continuous action space
- the critic’s output is the estimated Q-value of the current state and the action given by the actor
- the deterministic policy gradient theorem provides the update rule for the weights of the actor network
- the critic network is updated from the gradient obtained from the TD error signal
- Key Characteristics
- In general, temporally-correlated trajectories leads to the introduction enormous amounts of variance.
- Use replay buffer to store the experience of the agent during training, and then randomly sample experiences to use for learning in order to break up the temporal correlations experience reply
- directly updating actor and critic network with gradient from TD error causes divergence.
- using a set of target network to generate the target for your TD error and increases stability
here are the equations for the TD target 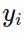 and the loss function for the critic network:
and the loss function for the critic network:
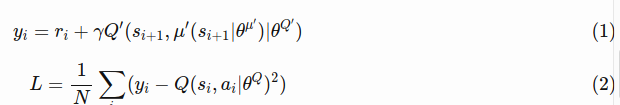
a minibatch of size N has been sampled from the replay buffer, with i index referring to the i th sample. The TD target is computed from target actor and critic network having weights.
The weights of the critic network can be updated with the gradients obtained from the loss function in Eq.2. Also, the actor network is updated with the Deterministic Policy Gradient.
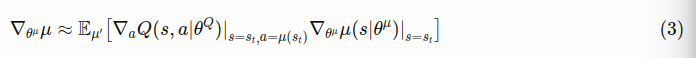
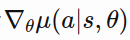
All you need is the gradient of the output of the critic network with respect to the actions, multiplied by the gradient of the output of the actor network with respect to the its parameters, averaged over a minibatch.

Eq.6 is exactly what we want.
Pendulum Example
Pendulum has a low dimensional state space and a single continuous action within [-2,2] the goal is to swing up and balance the pendulum
- set up a data structure to represent your replay buffer
- deque from python’s collection library
- the replay buffer will return a randomly chosen batch of experience when queried
from collections import deque
import random
import numpy as np
class ReplayBuffer(object):
def __init__(self, buffer_size, random_seed=123):
"""
The right side of the deque contains the most recent experiences
"""
self.buffer_size = buffer_size
self.count = 0
self.buffer = deque()
random.seed(random_seed)
.....
def sample_batch(self, batch_size):
batch = []
if self.count < batch_size:
batch = random.sample(self.buffer, self.count)
else:
batch = random.sample(self.buffer, batch_size)
s_batch = np.array([_[0] for _ in batch])
a_batch = np.array([_[1] for _ in batch])
r_batch = np.array([_[2] for _ in batch])
t_batch = np.array([_[3] for _ in batch])
s2_batch = np.array([_[4] for _ in batch])
return s_batch, a_batch, r_batch, t_batch, s2_batch
- actor-critic network
- tflearn to condense the boilerplate code
import tflearn
class ActorNetwork(object):
def create_actor_network(self):
# s_dim = state_dim
inputs = tflearn.input_data(shape=[None, self.s_dim])
net = tflearn.fully_connected(inputs, 400)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
net = tflearn.fully_connected(net, 300)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
# Final layer weights are init to Uniform[-3e-3, 3e-3]
w_init = tflearn.initializations.uniform(minval=-0.003, maxval=0.003)
out = tflearn.fully_connected(
net, self.a_dim, activation='tanh', weights_init=w_init)
# Scale output to -action_bound to action_bound
scaled_out = tf.multiply(out, self.action_bound)
return inputs, out, scaled_out
class CriticNetwork(object):
def create_critic_network(self):
inputs = tflearn.input_data(shape=[None, self.s_dim])
action = tflearn.input_data(shape=[None, self.a_dim])
net = tflearn.fully_connected(inputs, 400)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
# net is (?,400)
# Add the action tensor in the 2nd hidden layer
# Use two temp layers to get the corresponding weights and biases
t1 = tflearn.fully_connected(net, 300)
t2 = tflearn.fully_connected(action, 300)
# t1 is (400,300)
# t2 is (400,300)
# tf.matmul(net, t1.W) is (?,300): (?,400)*(400 X 300)
# net is (?,300)
net = tflearn.activation(
tf.matmul(net, t1.W) + tf.matmul(action, t2.W) + t2.b, activation='relu')
# linear layer connected to 1 output representing Q(s,a)
# Weights are init to Uniform[-3e-3, 3e-3]
w_init = tflearn.initializations.uniform(minval=-0.003, maxval=0.003)
# out is (?,1)
out = tflearn.fully_connected(net, 1, weights_init=w_init)
return inputs, action, out
tflearn.input_data tflearn.fullyconnected tflearn.layers.normalization.batch_normalization tflearn.activations.relu tflearn.initalizations.uniform tflearn.activation
-
the actor network, the output is a tanh layer scaled to be between
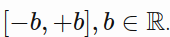 . This is useful when your action space is on the real line but is bounded and closed, as is the case for the pendulum task.
. This is useful when your action space is on the real line but is bounded and closed, as is the case for the pendulum task. -
critic network takes both the state and the action as inputs; however the action input skips the first layer. This is a design decision that has experimentally worked well.
Critic network
- critic network has two input_data(state,action)-> inputs,action
- inputs -> 400 fully connected layer -> batch_normalization-> relu output:net
- relu output -> 300 fully connected layer -> t1
- action -> 300 fully connected layer -> t2
- net updated : activation relu( matmul(net(relu output),t1.W) + matmul(action,t2.W)+ t2.b)
- w_init(-0.003,0.003)
- out = fully_connected(net,1,weights_init=w_init)
final output is estimated current state-action value
Actor network
- inputs : [None,self.s_dim] -> 400 fully connected layer -> batch_normalization -> relu -> 300 fully connected layer -> batch_normalization -> relu output
- w_init(-0.003,0.003)
- out : tanh(relu output -> self.a_dim(action dimension),weights_init=w_init)
- scaled_out = (out * self.action_bound)
final output is action probabilities
Creation methods twice
-
once to create the actor and critic networks that will be used for training, and again to create your target actor and critic network
-
update the target network parameters like below
self.network_params = tf.trainable_variables()
self.target_network_params = tf.trainable_variables()[len(self.network_params):]
# Op for periodically updating target network with online network weights
self.update_target_network_params = \
[self.target_network_params[i].assign(tf.mul(self.network_params[i], self.tau) + \
tf.mul(self.target_network_params[i], 1. - self.tau))
for i in range(len(self.target_network_params))]
update_target_network_params that will copy the parameters of the online network with a mixing factor 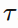 . This param is defined in both actor and critic network
. This param is defined in both actor and critic network
The Gradient computaion and optimization Tensorflow operations
- this is sort of replaced SGD
Actor network
- tf.gradients() implements Deterministic Policy Gradient Equation(Eq.4)
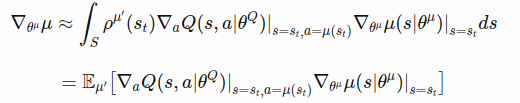
- tf.gradients() implements Deterministic Policy Gradient Equation(Eq.4)
tf.gradients tf.Adamoptimizer.apply_gradients
# This gradient will be provided by the critic network
self.action_gradient = tf.placeholder(tf.float32, [None, self.a_dim])
# Combine the gradients, dividing by the batch size to
# account for the fact that the gradients are summed over the
# batch by tf.gradients
self.unnormalized_actor_gradients = tf.gradients(
self.scaled_out, self.network_params, -self.action_gradient)
self.actor_gradients = list(map(lambda x: tf.div(x, self.batch_size), self.unnormalized_actor_gradients))
# Optimization Op
self.optimize = tf.train.AdamOptimizer(self.learning_rate).\
apply_gradients(zip(self.actor_gradients, self.network_params))
Critic network
- This is exactly Eq.2
- The action-value gradients at the end to pass to the policy network for gradient computation.
# Network target (y_i)
# Obtained from the target networks
self.predicted_q_value = tf.placeholder(tf.float32, [None, 1])
# Define loss and optimization Op
self.loss = tflearn.mean_square(self.predicted_q_value, self.out)
self.optimize = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss)
# Get the gradient of the net w.r.t. the action
self.action_grads = tf.gradients(self.out, self.action)
Main Function
- hyper parameters
import argparse
parser = argparse.ArgumentParser(description='provide arguments for DDPG agent')
# agent parameters
parser.add_argument('--actor-lr', help='actor network learning rate', default=0.0001)
parser.add_argument('--critic-lr', help='critic network learning rate', default=0.001)
parser.add_argument('--gamma',help='discount factor for critic updates',default=0.99)
parser.add_argument('--tau',help='soft target update parameter',default=0.001)
parser.add_argument('--buffer-size',help='max size of the replay buffer',default=1000000)
parser.add_argument('minibatch-size',help='size of minibatch for minibatch-SGD',default=64)
# run parameters
parser.add_argument('--env',help='choose the gym env- tested on {Pendulum-v0}',default='Pendulum-v0')
parser.add_argument('--random-seed',help='random seed for repeatability',default=1234)
parser.add_argument('--max-episodes',help='max num of episodes to do while training',default=50000)
parser.add_argument('--max-episodes-len',help='max length of 1 episode',dafault=1000)
parser.add_argument('--render-env',help='render the gym env',action='store_true')
parser.add_argument('--use-gym-monitor', help='record gym results', action='store_true')
parser.add_argument('--monitor-dir', help='directory for storing gym results', default='./results/gym_ddpg')
parser.add_argument('--summary-dir', help='directory for storing tensorboard info', default='./results/tf_ddpg')
parser.set_defaults(render_env=False)
parser.set_defaults(use_gym_monitor=True)
args = vars(parser.parse_args())
>> args['env']
>> 'Pendulum-v0'
def main(args):
with tf.Session() as sess:
env = gym.make(args['env']) # args['env'] : 'Pendulum-v0'
np.random.seed(int(args['random_seed'])) # args['random_seed'] : 1234
tf.set_random_seed(int(args['random_seed']))
env.seed(int(args['random_seed']))
state_dim = env.observation_space.shape[0] # state_dim 3
action_dim = env.action_space.shape[0] # action_dim 1
action_bound = env.action_space.high # action_bound [2.] numpy.ndarray
# Ensure action bound is symmetric
assert (env.action_space.high == -env.action_space.low)
actor = ActorNetwork(sess, state_dim, action_dim, action_bound,
float(args['actor_lr']), float(args['tau']),
int(args['minibatch_size']))
critic = CriticNetwork(sess, state_dim, action_dim,
float(args['critic_lr']), float(args['tau']),
float(args['gamma']),
actor.get_num_trainable_vars())
actor_noise = OrnsteinUhlenbeckActionNoise(mu=np.zeros(action_dim))
if args['use_gym_monitor']:
if not args['render_env']:
env = wrappers.Monitor(
env, args['monitor_dir'], video_callable=False, force=True)
else:
env = wrappers.Monitor(env, args['monitor_dir'], force=True)
train(sess, env, args, actor, critic, actor_noise)
if args['use_gym_monitor']:
env.monitor.close()
DDPG Algorithm

def train(sess, env, args, actor, critic, actor_noise):
# Set up summary Ops
# summary_ops is tf.summary.merge_all()
# summary_vars :[episode_reward, episode_ave_max_q] => [tf.Variable(0.),tf.Variable(0.)]
summary_ops, summary_vars = build_summaries()
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter(args['summary_dir'], sess.graph)
# Initialize target network weights
# self.sess.run(self.update_target_network_params) in actor
actor.update_target_network()
critic.update_target_network()
# Initialize replay memory
replay_buffer = ReplayBuffer(int(args['buffer_size']), int(args['random_seed']))
# Needed to enable BatchNorm.
# This hurts the performance on Pendulum but could be useful
# in other environments.
# tflearn.is_training(True)

for i in range(int(args['max_episodes'])):
s = env.reset()
ep_reward = 0
ep_ave_max_q = 0
for j in range(int(args['max_episode_len'])):
if args['render_env']:
env.render()
# Added exploration noise
#a = actor.predict(np.reshape(s, (1, 3))) + (1. / (1. + i))
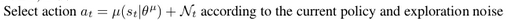
# self.sess.run(self.scaled_out, feed_dict={self.inputs: inputs})
# input is current state and scaled_out is estimated action output including bound
a = actor.predict(np.reshape(s, (1, actor.s_dim))) + actor_noise()
s2, r, terminal, info = env.step(a[0])
replay_buffer.add(np.reshape(s, (actor.s_dim,)), np.reshape(a, (actor.a_dim,)), r,
terminal, np.reshape(s2, (actor.s_dim,)))
# Keep adding experience to the memory until
# there are at least minibatch size samples
if replay_buffer.size() > int(args['minibatch_size']):
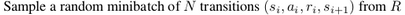
s_batch, a_batch, r_batch, t_batch, s2_batch = \
replay_buffer.sample_batch(int(args['minibatch_size']))
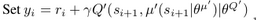
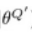 : critic target network
: critic target network
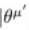 : actor target network
: actor target network
# Calculate targets
# critic.predict_target => self.sess.run(self.target_out,
# feed_dict={self.target_inputs: inputs,self.target_action: action})
# self.target_action => actor.predict_target(s2_batch) =>
# self.sess.run(self.target_scaled_out, feed_dict={self.target_inputs: inputs})
target_q = critic.predict_target(
s2_batch, actor.predict_target(s2_batch))
y_i = []
for k in range(int(args['minibatch_size'])):
if t_batch[k]:
y_i.append(r_batch[k])
else:
y_i.append(r_batch[k] + critic.gamma * target_q[k])
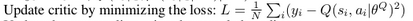
# Update the critic given the targets
# self.sess.run([self.out, self.optimize], feed_dict={
# self.inputs: inputs,
# self.action: action,
# self.predicted_q_value: predicted_q_value})
# predicted_q_value is y_i : td_target
# critic train minimizes the loss function
predicted_q_value, _ = critic.train(
s_batch, a_batch, np.reshape(y_i, (int(args['minibatch_size']), 1)))
ep_ave_max_q += np.amax(predicted_q_value)
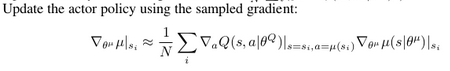
# Update the actor policy using the sampled gradient
# a_outs is below:
# self.sess.run(self.scaled_out, feed_dict={
# self.inputs: inputs})
# s_batch is current state
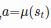 => a_outs from actor.predict(s_batch)
=> a_outs from actor.predict(s_batch)
a_outs = actor.predict(s_batch)
# self.sess.run(self.action_grads, feed_dict={
# self.inputs: inputs,self.action: actions})
# self.action_grads = tf.gradients(self.out, self.action)
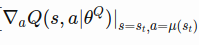 => action grdients of critic Q(s,a) => grads
=> action grdients of critic Q(s,a) => grads
grads = critic.action_gradients(s_batch, a_outs)
# self.sess.run(self.optimize, feed_dict={
# self.inputs: inputs,self.action_gradient: a_gradient})
# self.optimize = tf.train.AdamOptimizer(self.learning_rate).\
# apply_gradients(zip(self.actor_gradients, self.network_params))
# Combine the gradients here
# self.unnormalized_actor_gradients = tf.gradients(
# self.scaled_out, self.network_params, -self.action_gradient)
# self.actor_gradients = list(map(lambda x: tf.div(x,self.batch_size),
# self.unnormalized_actor_gradients))
# [self.scaled_out -> ys in tf.gradients]
# [-self.action_gradient -> initial gradients for each y in ys in tf.gradients]
# [self.network_params -> xs in tf.gradients]
# grads_and_vars: List of (gradient, variable) in apply_gradients
# => zip(self.actor_gradients, self.network_params)
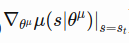 =>
=> 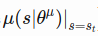 : actor network output(scaled_out) and
: actor network output(scaled_out) and 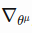 : self.network_params(network weights) gradients
: grad_ys input in tf.gradients(grad_ys) ,-self.action_gradient in code
: self.network_params(network weights) gradients
: grad_ys input in tf.gradients(grad_ys) ,-self.action_gradient in code
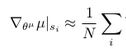 => self.actor_gradients = list(map(lambda x: tf.div(x, self.batch_size), self.unnormalized_actor_gradients))
=> self.actor_gradients = list(map(lambda x: tf.div(x, self.batch_size), self.unnormalized_actor_gradients))
actor.train(s_batch, grads[0])
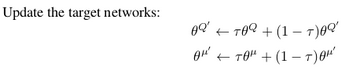
# Update target networks
# # weights
# self.update_target_network_params = \
# [self.target_network_params[i].assign(tf.multiply(
# self.network_params[i], self.tau) +
# tf.multiply(self.target_network_params[i], 1. - self.tau))
# for i in range(len(self.target_network_params))]
actor.update_target_network()
critic.update_target_network()
s = s2
ep_reward += r
if terminal:
summary_str = sess.run(summary_ops, feed_dict={
summary_vars[0]: ep_reward,
summary_vars[1]: ep_ave_max_q / float(j)
})
writer.add_summary(summary_str, i)
writer.flush()
print('| Reward: {:d} | Episode: {:d} | Qmax: {:.4f}'.format(int(ep_reward), \
i, (ep_ave_max_q / float(j))))
break
tf.trainable_variables python map_function tf.AdamOptimizer
def main(args):
with tf.Session() as sess:
env = gym.make(args['env'])
np.random.seed(int(args['random_seed']))
tf.set_random_seed(int(args['random_seed']))
env.seed(int(args['random_seed']))
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high
# Ensure action bound is symmetric
assert (env.action_space.high == -env.action_space.low)
actor = ActorNetwork(sess, state_dim, action_dim, action_bound,
float(args['actor_lr']), float(args['tau']),
int(args['minibatch_size']))
critic = CriticNetwork(sess, state_dim, action_dim,
float(args['critic_lr']), float(args['tau']),
float(args['gamma']),
actor.get_num_trainable_vars())
actor_noise = OrnsteinUhlenbeckActionNoise(mu=np.zeros(action_dim))
if args['use_gym_monitor']:
if not args['render_env']:
env = wrappers.Monitor(
env, args['monitor_dir'], video_callable=False, force=True)
else:
env = wrappers.Monitor(env, args['monitor_dir'], force=True)
train(sess, env, args, actor, critic, actor_noise)
if args['use_gym_monitor']:
env.monitor.close()