Basic Cart Pole DQN
CartPole Basic
- start cartpole environment and take random actions
import gym
env = gym.make("CartPole-v0")
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())# take random action
- reward for 10 episodes
import gym
env = gym.make("CartPole-v0")
env.reset()
random_episodes = 0
reward_sum = 0
while random_episodes < 10:
env.render()
action = env.action_space.sample()
observation,reward,done,_ = env.step(action)
print(observation,reward,done)
reward_sum += reward
if done:
random_episodes += 1
print("Reward for this episode was:",reward_sum)
reward_sum = 0
env.reset()
>> [ 0.03342757 -0.201816 0.01211287 0.27697714] 1.0 False
[ 0.02939125 -0.00686893 0.01765242 -0.0118609 ] 1.0 False
[ 0.02925387 0.18799547 0.0174152 -0.29892243] 1.0 False
[ 0.03301378 -0.00737034 0.01143675 -0.00079834] 1.0 False
[ 0.03286638 0.18758574 0.01142078 -0.28985101] 1.0 False
[ 0.03661809 0.38254299 0.00562376 -0.57891017] 1.0 False
[ 0.04426895 0.57758568 -0.00595444 -0.8698162 ] 1.0 False
[ 0.05582066 0.77278812 -0.02335076 -1.16436527] 1.0 False
[ 0.07127643 0.96820616 -0.04663807 -1.46427691] 1.0 False
[ 0.09064055 1.16386736 -0.07592361 -1.7711562 ] 1.0 False
[ 0.1139179 1.35975938 -0.11134673 -2.08644785] 1.0 False
[ 0.14111308 1.16592433 -0.15307569 -1.83016414] 1.0 False
[ 0.16443157 0.97279386 -0.18967897 -1.58868461] 1.0 False
[ 0.18388745 1.16959514 -0.22145266 -1.93402385] 1.0 True
Reward for this episode was: 14.0
...
Reward for this episode was: 16.0
Reward for this episode was: 44.0
Reward for this episode was: 18.0
Reward for this episode was: 19.0
Reward for this episode was: 35.0
Reward for this episode was: 15.0
Reward for this episode was: 16.0
Reward for this episode was: 30.0
Reward for this episode was: 18.0
Reward for this episode was: 13.0
- Rewards

# Get new state and reward from environment
s1,reward,done,_ = env.step(a)
if done:
Qs[0,a] = -100 # fall down -> reward (-100)
else:
x1 = np.reshape(s1,[1,input_size])
Qs1 = sess.run(Qpred,feed_dict = {X:x1})
Qs[0,a] = reward + dis*np.max(Qs1)
- Cart Pole Q network
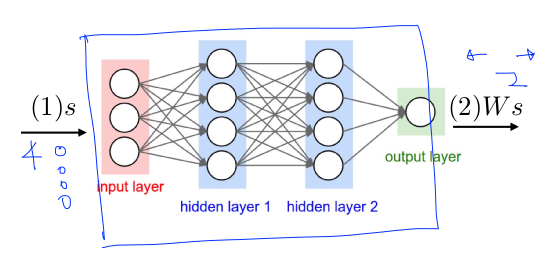
- 4 state inputs
- 2 actions outputs
- Cart Pole QNetwork construction
input_size = env.observation_space.shape[0] # 4
output_size = env.action_space.n # 2
X = tf.placeholder(tf.float32,[None,input_size],name = "input_x")
# First layer weight
W1 = tf.get_variable("W1",shape=[input_size,output_size],initializer=tf.contrib.layers.xavier_initializer())
Qpred = tf.matmul(X,W1)
- Qnetwork training(linear regression)
# we need to define the parts of the network needed for learning a policy
Y = tf.placeholder(shape=[None,output_size],dtype = tf.float32)
# loss function
loss = tf.reduce_mean(tf.square(Y-Qpred))
# learning
train = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(loss)
...
# a -> 1 x 2 array
Qs[0,a] = reward + dis * np.max(Qs1)
sess.run(train,feed_dict={X:x,Y:Qs})
import numpy as np
import tensorflow as tf
from collections import deque
import gym
env = gym.make('CartPole-v0')
# Constants defining our neural network
learning_rate = 1e-1
input_size = env.observation_space.shape[0]
output_size = env.action_space.n
X = tf.placeholder(tf.float32, [None, input_size], name="input_x")
# First layer of weights
W1 = tf.get_variable("W1", shape=[input_size, output_size],
initializer=tf.contrib.layers.xavier_initializer())
Qpred = tf.matmul(X, W1)
# We need to define the parts of the network needed for learning a policy
Y = tf.placeholder(shape=[None, output_size], dtype=tf.float32)
# Loss function
loss = tf.reduce_sum(tf.square(Y - Qpred))
# Learning
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
# Values for q learning
max_episodes = 1#5000
dis = 0.9
step_history = []
# Setting up our environment
init = tf.global_variables_initializer()
sess = tf.InteractiveSession()
sess.run(init)
state = env.reset()
x = np.reshape(state, [1, input_size])
Q = sess.run(Qpred, feed_dict={X: x})
Q.shape # action outputs dimension
>> (1,2)
action = env.action_space.sample()
next_state, reward, done, _ = env.step(action)
x_next = np.reshape(next_state, [1, input_size])
Q_next = sess.run(Qpred, feed_dict={X: x_next})
# action 0 or 1 -> Q[0,0] or Q[0,1] updated
Q[0, action] = reward + dis * np.max(Q_next)
action
>> 1
Q_next
>>
array([[ 0.12043852, -0.07847758]], dtype=float32)
reward + dis * np.max(Q_next)
>>1.1976611286401748
Q # Q[0,1] updated
>> array([[1.0181861, 1.1976612]], dtype=float32)
- Full codes

import numpy as np
import tensorflow as tf
from collections import deque
import gym
env = gym.make('CartPole-v0')
# Constants defining our neural network
learning_rate = 1e-1
input_size = env.observation_space.shape[0]
output_size = env.action_space.n
X = tf.placeholder(tf.float32, [None, input_size], name="input_x")
# First layer of weights
W1 = tf.get_variable("W1", shape=[input_size, output_size],
initializer=tf.contrib.layers.xavier_initializer())
Qpred = tf.matmul(X, W1)
# We need to define the parts of the network needed for learning a policy
Y = tf.placeholder(shape=[None, output_size], dtype=tf.float32)
# Loss function
loss = tf.reduce_sum(tf.square(Y - Qpred))
# Learning
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
# Values for q learning
max_episodes = 5000
dis = 0.9
step_history = []
# Setting up our environment
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for episode in range(max_episodes):
e = 1. / ((episode / 10) + 1)
step_count = 0
state = env.reset()
done = False
# The Q-Network training
while not done:
step_count += 1
x = np.reshape(state, [1, input_size])
# Choose an action by greedily (with e chance of random action) from
# the Q-network
Q = sess.run(Qpred, feed_dict={X: x})
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
action = np.argmax(Q)
# Get new state and reward from environment
next_state, reward, done, _ = env.step(action)
if done:
Q[0, action] = -100
else:
x_next = np.reshape(next_state, [1, input_size])
# Obtain the Q' values by feeding the new state through our network
Q_next = sess.run(Qpred, feed_dict={X: x_next})
Q[0, action] = reward + dis * np.max(Q_next)
# Train our network using target and predicted Q values on each episode
sess.run(train, feed_dict={X: x, Y: Q})
state = next_state
step_history.append(step_count)
print("Episode: {} steps: {}".format(episode, step_count))
# If last 10's avg steps are 500, it's good enough
if len(step_history) > 10 and np.mean(step_history[-10:]) > 500:
break
# See our trained network in action
observation = env.reset()
reward_sum = 0
while True:
env.render()
x = np.reshape(observation, [1, input_size])
Q = sess.run(Qpred, feed_dict={X: x})
action = np.argmax(Q)
observation, reward, done, _ = env.step(action)
reward_sum += reward
if done:
print("Total score: {}".format(reward_sum))
break
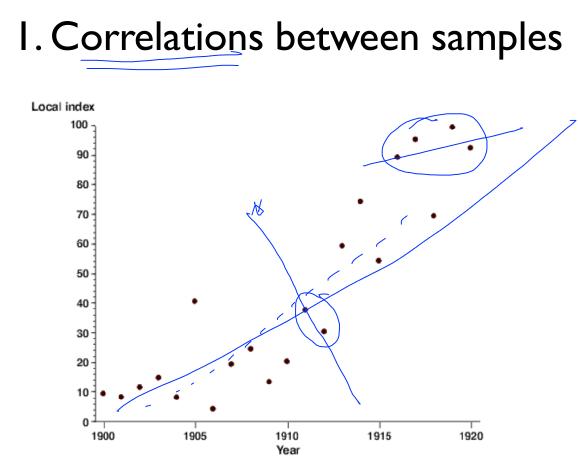
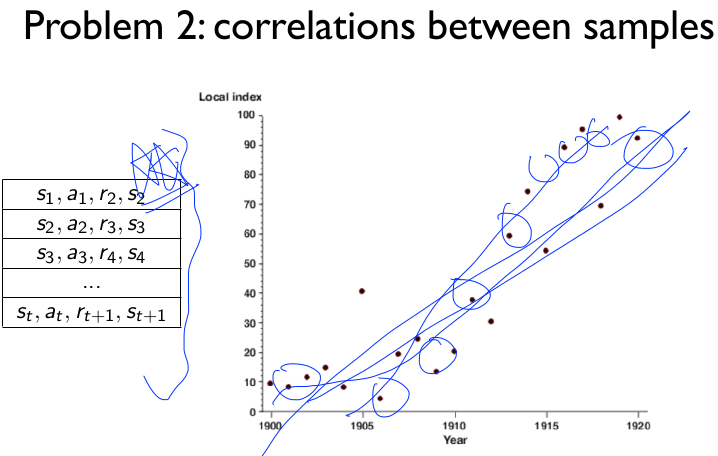
Result is very bad. diverges using neural networks due to
- correlation between samples
- Non-stationary targets
- Network shallow


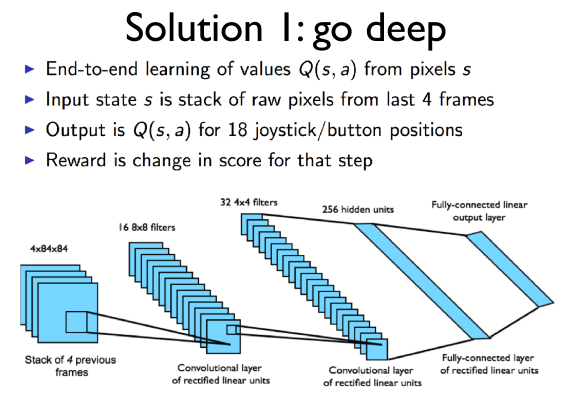
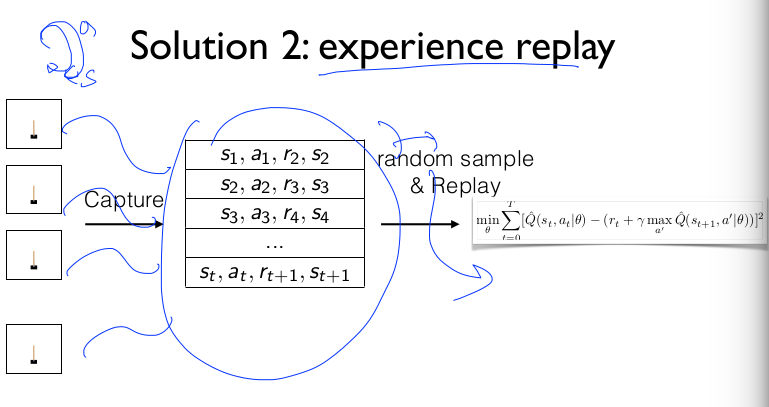
DQN has three solutions
- Go Deep
- Capture and replay
- Correlation between samples
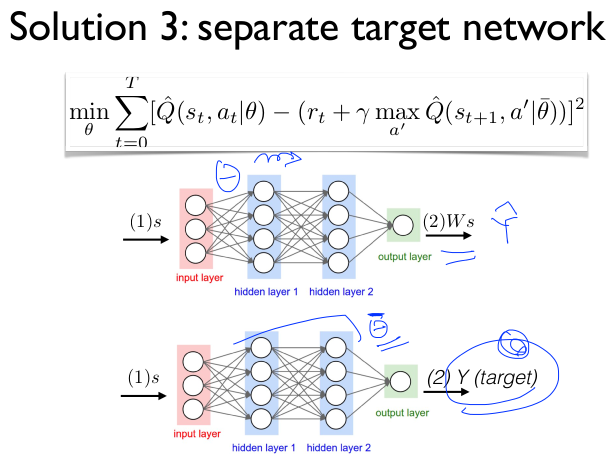
- Seperate network:create a target network
- Non-stationary targets
Go Deep
Capture and Replay
Seperate target network
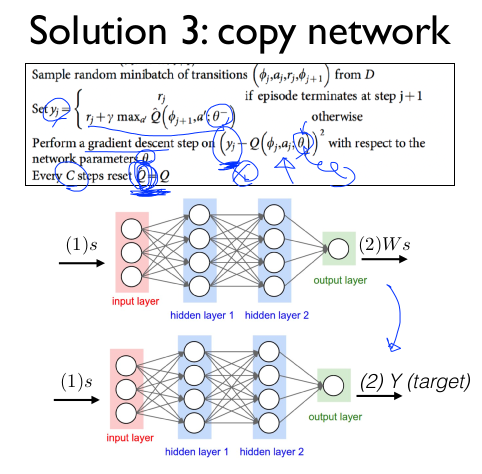
DQN nature paper 2015

DQN 2013 nature code
gym setting parameters
import numpy as np
import tensorflow as tf
import random
import dqn
import gym
from collections import deque
env = gym.make('CartPole-v0')
env = gym.wrappers.Monitor(env, 'gym-results/', force=True)
INPUT_SIZE = env.observation_space.shape[0] # 4
OUTPUT_SIZE = env.action_space.n # 2
DISCOUNT_RATE = 0.99
REPLAY_MEMORY = 50000
MAX_EPISODE = 5000
BATCH_SIZE = 64
# minimum epsilon for epsilon greedy
MIN_E = 0.0
# epsilon will be `MIN_E` at `EPSILON_DECAYING_EPISODE`
EPSILON_DECAYING_EPISODE = MAX_EPISODE * 0.01
main funciton
def main():
# store the previous observations in replay memory
replay_buffer = deque(maxlen=REPLAY_MEMORY)
last_100_game_reward = deque(maxlen=100)
with tf.Session() as sess:
mainDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE)
init = tf.global_variables_initializer()
sess.run(init)
for episode in range(MAX_EPISODE):
e = annealing_epsilon(episode, MIN_E, 1.0, EPSILON_DECAYING_EPISODE)
done = False
state = env.reset()
step_count = 0
while not done:
if np.random.rand() < e:
action = env.action_space.sample()
else:
action = np.argmax(mainDQN.predict(state))
next_state, reward, done, _ = env.step(action)
if done:
reward = -1
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
step_count += 1
if len(replay_buffer) > BATCH_SIZE:
minibatch = random.sample(replay_buffer, BATCH_SIZE)
train_minibatch(mainDQN, minibatch)
print("[Episode {:>5}] steps: {:>5} e: {:>5.2f}".format(episode, step_count, e))
# CartPole-v0 Game Clear Logic
last_100_game_reward.append(step_count)
if len(last_100_game_reward) == last_100_game_reward.maxlen:
avg_reward = np.mean(last_100_game_reward)
if avg_reward > 199.0:
print("Game Cleared within {} episodes with avg reward {}".format(episode, avg_reward))
break
class DQN
class DQN:
...
def _build_network(self, h_size=16, l_rate=0.001) -> None:
"""DQN Network architecture (simple MLP)
Args:
h_size (int, optional): Hidden layer dimension
l_rate (float, optional): Learning rate
"""
with tf.variable_scope(self.net_name):
self._X = tf.placeholder(tf.float32, [None, self.input_size], name="input_x")
net = self._X
net = tf.layers.dense(net, h_size, activation=tf.nn.relu)
net = tf.layers.dense(net, self.output_size)
self._Qpred = net
self._Y = tf.placeholder(tf.float32, shape=[None, self.output_size])
self._loss = tf.losses.mean_squared_error(self._Y, self._Qpred)
optimizer = tf.train.AdamOptimizer(learning_rate=l_rate)
self._train = optimizer.minimize(self._loss)
...
training network
def train_minibatch(DQN: dqn.DQN, train_batch: list) -> float:
state_array = np.vstack([x[0] for x in train_batch])
action_array = np.array([x[1] for x in train_batch])
reward_array = np.array([x[2] for x in train_batch])
next_state_array = np.vstack([x[3] for x in train_batch])
done_array = np.array([x[4] for x in train_batch])
X_batch = state_array
y_batch = DQN.predict(state_array)
Q_target = reward_array + DISCOUNT_RATE * np.max(DQN.predict(next_state_array), axis=1) * ~done_array
y_batch[np.arange(len(X_batch)), action_array] = Q_target
# Train our network using target and predicted Q values on each episode
loss, _ = DQN.update(X_batch, y_batch)
return loss
import numpy as np
a = np.arange(5)
b = np.arange(5,10)
c = np.arange(10.15)
print(a,b)
>> [0 1 2 3 4] [5 6 7 8 9]
x = np.vstack([a,b])
print(x)
>> [[0 1 2 3 4]
[5 6 7 8 9]]
train_batch = x
# for x in train_batch:
# print(x,x[0])
state_array = np.vstack([x[0] for x in train_batch])
action_array = np.array([x[1] for x in train_batch])
print (state_array,action_array)
>> [[0]
[5]] [1 6]